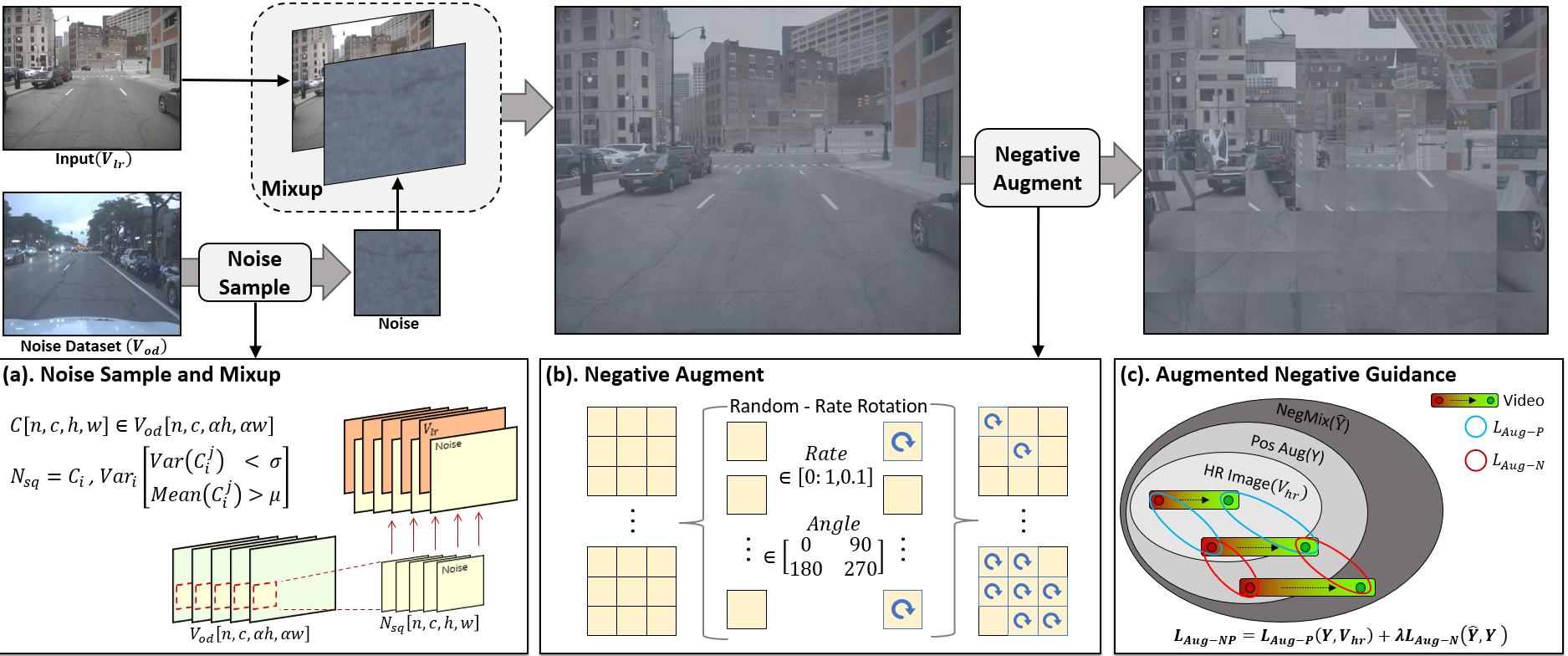
NegVSR: Augmenting Negatives for Generalized Noise Modeling in Real-world Video Super-Resolution
Video Demos:
Abstract
The capability of video super-resolution (VSR) to synthesize high-resolution (HR) video from ideal datasets has been demonstrated in many works. However, applying the VSR model to real-world video with unknown and complex degradation remains a challenging task. First, existing degradation metrics in most VSR methods are not able to effectively simulate real-world noise and blur. On the contrary, simple combinations of classical degradation are used for real-world noise modeling, which led to the VSR model often being violated by out-of-distribution noise. Second, many SR models focus on noise simulation and transfer. Nevertheless, the sampled noise is monotonous and limited. To address the aforementioned problems, we propose a Negatives augmentation strategy for generalized noise modeling in Video Super-Resolution (NegVSR) task. Specifically, we first propose sequential noise generation toward real-world data to extract practical noise sequences. Then, the degeneration domain is widely expanded by negative augmentation to build up various yet challenging real-world noise sets. We further propose the augmented negative guidance loss to learn robust features among augmented negatives effectively. Extensive experiments on real-world datasets (e.g., VideoLQ and FLIR) show that our method outperforms state-of-the-art methods with clear margins, especially in visual quality.
Keywords: real-world video super-resolution, noise sequences sampling, negative augmentation, augmented negative guidance
Framework
The overview of the proposed NegVSR. (a) Our approach initially extracts noise sequence Nsq through window sequence C in an unsupervised manner. The motion of C occurs within the OOD video noise dataset Vod. Subsequently, it mixes Nsq and LR video Vlr to create novel training input VlrN. (b) VlrN is applied with a patch-based random central rotation to derive Vneg. (c) Both Vneg and Vlr are fed into the VSR model to generate Ŷ and Y, respectively. And LAug-P enables the model to recover more effective pixels from the Vlr. LAug-N drives Y to learn the robust features present in the negative output Ŷ.
Method
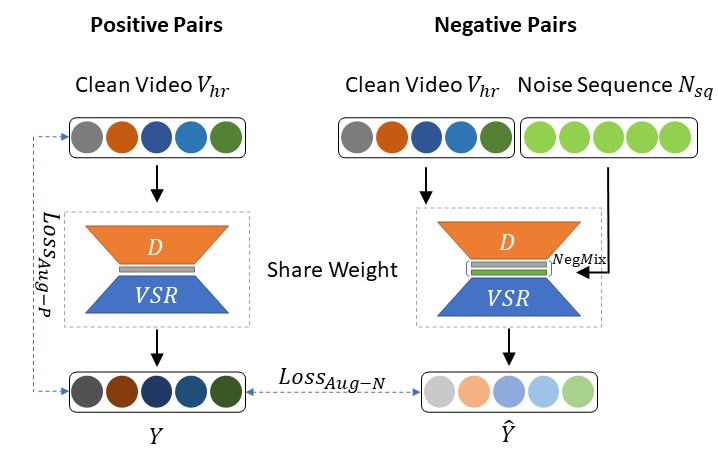
The figure depicts the process of our Augmented Negative Guidance approach. We obtain the positive output Ŷ by passing Vhr sequential through the degeneration model D and VSR. Then we inject noise sequence Nsq into the degraded video and apply the video with negative augmentation. Finally, we encourage the model to learn robust features from the augmented noise and video by LAug-N and LAug-P.
Results: compare with other methods
More details: